Spark Operations-Transformations & Actions
- Murat Can ÇOBAN

- Jan 26, 2022
- 2 min read
In this article, we will examine RDD ("Resilient Distributed Dataset). I will try to explain the operations on RDD with examples. We will examine it under two topics, Transformation and Action.
First of all, we import the libraries we need. Then we create a SparkSession according to your own computer hardware.
from pyspark.sql import SparkSession
from pyspark.conf import SparkConf
spark = SparkSession.builder\
.master("local[2]")\
.appName("RDD-Olusturmak")\
.config("spark.executor.memory","4g")\
.config("spark.driver.memory","2g")\
.getOrCreate()
sc = spark.SparkContext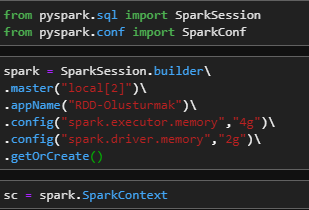
CREATE A RDD
liste = [1,2,3,4,5,6,6,8,4,1]
liste_rdd = sc.parallelize(liste)
liste_rdd.take(10)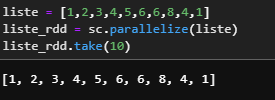
TRANSFORMATIONS
Filter
Map
flatMap
Union
Intersection
Subtract
Distinct
Sample
Let's examine our action functions as examples by creating an example RDD as below.
liste = [1,2,3,4,5,6,6,8,4,1]
liste_rdd = sc.parallelize(liste)
liste_rdd.take(10)a) Filter
Creates a new RDD by filtering the values in the RDD based on the given conditions.
liste_rdd.filter(lambda x : x < 7).take(10)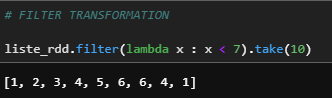
b) Map
Returns a new RDD by applying a function to each element of the RDD.
liste_rdd.map(lambda x : x*x).take(10)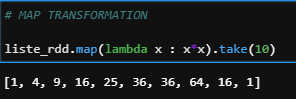
c) flatMap
Returns a new RDD by applying a function to the letters inside each element of the RDD.
metin = ["emel eve gel","ali ata bak", "ahmet okula git"]
metin_Rdd = sc.parallelize(metin)
metin_Rdd.take(3)
metin_Rdd.flatMap(lambda x : x.split(" ")).take(3)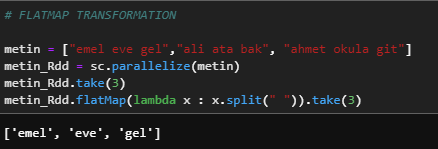
d) Union
Used to combine two RDD's of the same structure/schema. If schemas are not the same it returns an error.
rdd2 = sc.parallelize([64,1,9,7,6,7,61,4])
rdd3 = sc.parallelize([658,4,3,1,1,2134])
rdd2.union(rdd3).take(50)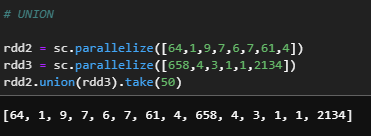
e) Intersection
Return the intersection of this RDD and another one. The output will not contain any duplicate elements, even if the input RDDs did.
rdd2.intersection(rdd3).take(54)
f) Subtract
Return a new RDD containing rows in this RDD but not in another RDD.
rdd2.subtract(rdd3).take(10)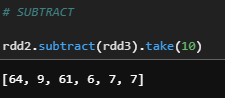
e) Distinct
Return a new RDD containing the distinct elements in this RDD.
liste_rdd.distinct().take(10)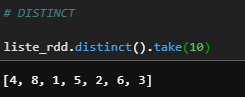
f) Sample
Returns a sampled subset of this RDD.
liste_rdd.sample(True, 0.7, 31).take(10)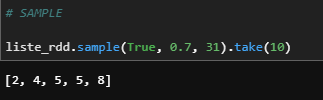
ACTIONS
Take
Collect
Count
Top
Reduce
countByValue
takeOrdered
Let's examine our action functions as examples by creating an example RDD as below.
ornek = [1,2,3,4,5,6,6,8,4,1]
ornek_rdd = sc.parallelize(liste)
ornek_rdd.take(10)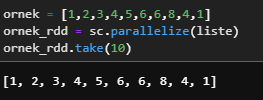
a) Take
Take the first num elements of the RDD.
ornek_rdd.take(7)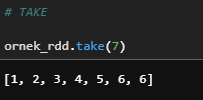
b) Collect
Returns all the records as a list of row.
ornek_rdd.collect()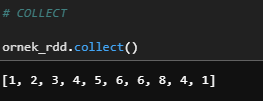
c) Count
Returns the number of rows in this RDD.
ornek_rdd.count()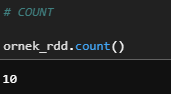
d) Top
Get the top N elements from an RDD.
ornek_rdd.top(5)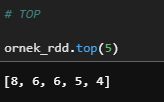
e) Reduce
Aggregate action function is used to calculate min, max, and total of elements in a dataset.
ornek_rdd.reduce(lambda x,y : x+y)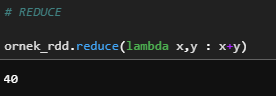
f) countByValue
Return the count of each unique value in this RDD as a dictionary of (value, count) pairs.
ornek_rdd.countByValue()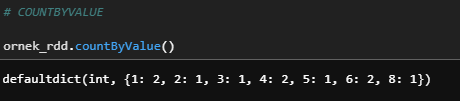
e) takeOrdered
Get the N elements from an RDD ordered in ascending order or as specified by the optional key function.
ornek_rdd.takeOrdered(7)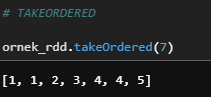
In this article, I tried to explain Spark operations with examples such as transformation and action.I hope it was useful.For your questions, you can reach the comments.
Hope to see you in new posts,
Take care.



Comments